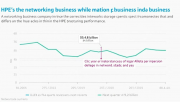
HPE���IJƼ�Ӫ�մ�97����Ԫ��ͬ������14%����������ҵ����Juniper�չ��ƶ��������150%��Ȼ��������Ӫ��45����Ԫ��ͬ���½�5%�������г���AI�������������ӡ�GreenLake����ҵ����Ⱦ�������������32����Ԫ��ͬ����������ϸ

Linux�ں�6.18����ʽ��ָ��Ϊ�µij���֧�ְ汾��Alpine Linux 3.23���ȴ��ظ��ں˷������°汾����APK 3.0.0���������ߣ��ṩ���ְ�װģʽ��������ģʽ��������ģʽ�ʹ�ͳϵͳ��ģʽ��Alpine֧��GNOME 49��KDE Plasm����ϸ

GartnerԤ�⣬��2029�꣬����50%����ҵ������������Ȩ���ԣ�ȷ�����Ҷ����ݺؼ�ϵͳ�Ŀ��ƣ����Ŀǰ����10%�ı��������������Ȩ�ƽ�����Щ�����з��ӹؼ����ã�������ҵ��������ȨҪ���ͬʱʵ��ϵͳ�����ݵ��ƻ�����ϸ

Meta�����չ�AI������˾Limitless���ù�˾������AI�����ĹҼ��豸��¼�ƶԻ����չ���Limitless��ֹͣӲ�����ۣ����пͻ��ɻ��һ��֧�֡���˾��ʼ�˱�ʾ������OpenAI��Meta�ȴ�����ҵ����Ӳ���������Ӿ�ʹ���ѡ���ϸ
2025���ǿƼ���̬����ԡ������캽 �ǻݹ�����Ϊ���⣬��۲�ҵ����̬��飬չʾ�Ƽ��������ҵЭͬ���³ɹ���̽�����ǿƼ���̬��չ���»���������ϸ
2025���ǿƼ���̬����ԡ������캽 �ǻݹ�����Ϊ���⣬��۲�ҵ����̬��飬չʾ�Ƽ��������ҵЭͬ���³ɹ���̽�����ǿƼ���̬��չ���»���������ϸ
11��28�գ���ΪHMS for Car������̳��������ɽ�ɹ��ٰ졣����ϸ
ÿ���12��3���ǹ��ʲм����ա�������������Ϊʼ�ռ�ּ����š��Ƽ��������κ�һ���˵��ӡ����������ϸ
�������ȵĴ洢��������ṩ�̡�оչ�١��ڱ��������������ɹ��ٰ� ���顤6�� ��Ʒ�����ᣬ�ذ��Ƴ���ȫ�沼�� PCIe Gen6 ʱ������ҵ�� SSD��Retimer ��ȫջ�������������ϸ
12��5�գ����й����������2025���ǿƼ���̬�������̳�ڹ����ٿ����������ԡ������캽 �ǻݹ�����Ϊ���⣬����������š���ҵ����������Ժ������ҵ��������ͬ̽���˹����ܡ�����ͨ�š��Ϳվ��õ�ǰ������ķ�չ������ϸ
����������ģ�ͼ����������Լ���Ӧ�Ļ�����ʩ����������������������ǰ��Ӧ�ò������ƣ��ƶ��˹����ܸ��������������ж����������������졢��Դ��ҽ�ơ����������Ⱦ��峡����������������еĸ������⣬ͬʱ�����롭��ϸ

������ʽ������������AI���������壬������ȫ�漤������Ϊ2026��FIFA���籭�ٷ���������������ݼ�����moto�ٷ������ֻ�����������ݡ�����ϸ
�����һ�ֿƼ������Ͳ�ҵ���Ľ���㣬�˹����ܡ�5G�����ǻ�������ǰ�ؼ����ںϴ��£����Լ�������Ϊ���濪��ȫ�±��ƪ�¡����й����������2025���ǿƼ���̬�����12��5��-7���ڹ��ݾٰ죬���δ���ԡ������캽 ����ϸ
12��5�գ��ԡ�����ӽ磬����ͬ�С�Ϊ�����BOE����������������ʾ������Դ����̳�ڳɶ��ɹ��ٰ졣��̳�����ѧ���硢��ҵ���������ڶඥ��ר��ѧ�����ҵ���������ͬ̽�ֽ�����ʾ������δ�������뷢չ����������ϸ
12��3�գ�2025��ҵ�Ҳ�����̳������ҵ�Ϲ潨�����������������չ��̳�ں��ϲ�����Ļ����Ϊ�й���ҵ������˼���ǻ�ʢ�磬�˴���̳�۽����ǻ�ת����ˮ���ĺϹ潨�������ϵ���⣬Ϊ��ʱ����ҵ��������չע��Ϲ桭��ϸ
������dz����е����˽�IT�������²�Ʒ�뼼����Ϣ����ô���������������ʼ������������;��֮һ��



