
阿里巴巴Qwen团队发布Qwen2.5-1M系列AI模型,实现百万字符长文本处理能力突破。该系列包含开源的7B和14B模型以及API版本Qwen2.5-Turbo,通过创新的训练策略和推理优化技术,让AI能够同时理解相当于四本《哈利・波特》…详细

KAIST研究团队开发的VideoRAG系统实现了人工智能在视频内容理解上的重大突破。该系统能够直接从海量视频中检索相关内容并生成准确答案,解决了传统方法只能处理文字和图片信息的局限。通过智能帧选择和多模态信息融合…详细

俄国科学家开发出共享记忆变换器(SRMT)技术,通过让机器人共享记忆而非直接通信来实现协作。该技术受人类大脑全局工作空间理论启发,让每个机器人都能访问共同的记忆池。在多项测试中,SRMT显著优于传统协作方法,…详细

香港大学与快手科技联合开发的GameFactory系统实现了革命性突破:用户只需文字描述就能生成可操作的互动游戏。该系统通过创新的"风格-动作解耦"技术,让AI既能理解游戏控制逻辑,又能适应任何场景环境,从《我的世界…详细

阿里巴巴研究团队发现传统AI专家混合模型训练中存在"大锅饭"问题:系统在每个小数据批次中都强制专家均衡分工,阻碍了专业化。他们提出全局批次负载均衡方法,让专家在更大数据范围内实现专业化分工,实验显示新方法…详细

阿联酋穆罕默德・本・扎耶德人工智能大学研究团队开发出LlamaV-o1,这是一个能够像人类一样进行分步视觉推理的AI系统。该系统通过课程学习和束搜索技术,不仅能给出正确答案,更能清晰展示每一步思考过程。研究团队还…详细

这项由清华大学和微软亚洲研究院合作完成的研究,通过创新的动态知识蒸馏和选择性遗忘机制,成功解决了AI系统在学习新任务时会遗忘旧知识的"灾难性遗忘"问题。该技术让AI能够像人类一样进行终身学习,在掌握新技能的…详细

清华大学研究团队开发出突破性的三维旋转优化方法,通过四维空间处理解决了困扰计算机图形学几十年的"万向节锁死"问题。该方法将旋转路径缩短15-25%,显著提升动画自然度,在用户测试中获得更高评分并能减少VR晕动症…详细

英美两国签署科技繁荣协议,推动人工智能、量子和核技术发展。英国政府投资440亿英镑,微软、英伟达、谷歌、OpenAI等承诺投资310亿英镑,目标建设欧洲最大AI工厂。协议包括联合研究计划,开发AI模型用于癌症等疾病的…详细

亚马逊宣布推出全天候AI代理,升级卖家助手工具,帮助第三方卖家运营业务。该AI助手不仅能监控账户健康状况和库存,还能制定策略并在授权下采取行动。功能包括标记滞销产品、分析需求模式、提供发货建议、确保产品合…详细

谷歌宣布为大学生免费提供最先进AI工具,这是科技巨头塑造未来劳动力的多亿美元竞争最新举措。通过10亿美元三年投资,谷歌AI教育加速器为美国大学生提供Gemini 2.5 Pro培训认证。这标志着高等教育从ChatGPT出现后的广…详细

前Twitter产品负责人Kayvon Beykpour推出AI驱动的代码理解引擎Macroscope,旨在帮助开发者和产品负责人总结代码库更新并捕获漏洞。该工具通过GitHub应用访问代码库,使用抽象语法树分析代码变化,结合大语言模型提供…详细

AI安全公司Irregular宣布完成8000万美元融资,由红杉资本和Redpoint Ventures领投,公司估值达4.5亿美元。该公司专注于AI模型安全评估,其SOLVE框架已被业界广泛采用,参与了Claude 3.7 Sonnet和OpenAI o3等模型的安…详细
在9月16日举办的2025年腾讯全球数字生态大会上,腾讯宣布正式推出专家服务智能体Cloud Mate。…详细
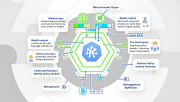
Solo.io推出的Kagent企业版通过扩展Kubernetes功能,为AI代理、工具和大语言模型提供上下文感知的基础设施。该平台包含三层架构:网络层支持模型上下文协议和代理间通信,运行时层扩展身份策略模型,管理层提供集中式…详细
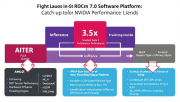
AMD推出ROCm 7.0软件平台,在推理性能上实现3.5倍提升,训练浮点性能提升3倍。该平台支持OCP微缩放数据类型硬件加速,引入AI张量引擎AITER,可将MLA解码操作提升17倍。结合MI355X芯片,AMD声称在DeepSeek R1推理负载…详细
互联网正进入AI代理主动推理和行动的新阶段。Perplexity推出AI驱动浏览器Comet,但新功能带来新风险。两家公司合作确保AI浏览的生产力提升不以安全为代价。Comet将AI直接融入浏览体验,能代表用户执行实际任务。1Pas…详细
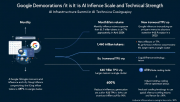
谷歌在AI基础设施峰会上披露了其AI推理的惊人规模增长。从2024年4月的9.7万亿tokens/月激增至2025年8月的约1460万亿tokens/月,增长49.5倍。公司推出全新Ironwood TPU v7p系统,性能比前代提升5倍,内存容量增加6倍,…详细

谷歌云发布代理支付协议AP2,旨在建立AI代理自主支付的全球安全标准。该协议与万事达、PayPal、美国运通等60多家公司合作开发,通过"授权书"系统建立防篡改的数字合约,确保交易可追溯性。AP2支持多种支付方式,可扩…详细
如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。



