近日,在北京举行的2025亿邦产业互联网年会上,亿邦董事长暨亿邦智库院长郑敏正式发布《2025年产业互联网发展报告》(以下简称“报告”),解锁“产业互联网新周期实践先锋图谱”,并首次重磅推出《2025新周期领航案…详细

大会期间,地平线开展智驾体验活动,除了高阶辅助驾驶量产样板间HSD,还携手众多合作伙伴,呈现覆盖不同场景、满足多阶需求的智驾生态全景。…详细
此项认可再次印证了 Check Point 以 AI 驱动的解决方案在抵御高级电子邮件威胁方面的卓越能力…详细
2025 年 12 月 11日,PTC宣布推出 Arena 产品生命周期管理(PLM)和质量管理系统(QMS)AI 引擎。…详细

Meta与华盛顿大学联合研究团队开发出无需人类标注的AI评判官自我训练框架。该方法通过生成合成对比数据、自我判断筛选和反复学习,使110亿参数的AI评判官在多项视觉语言任务中超越GPT-4o等大型模型,成本仅为传统方法…详细

华中科技大学团队开发出4DLangVGGT技术,首次实现AI系统对4D动态场景的语言理解。该技术突破传统方法需要逐场景训练的限制,能跨场景通用部署。系统结合几何感知和语义理解,不仅能识别物体还能描述其时间变化过程。…详细

微软亚洲研究院、西安交通大学和字节跳动联合提出语义优先扩散技术,通过模拟人类绘画"先整体后细节"的认知过程,将AI图像生成分为语义初始化、异步生成和纹理完善三个阶段。该技术在ImageNet数据集上实现了100倍训练…详细
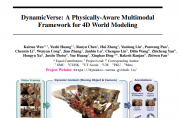
厦门大学联合多所顶尖院校开发出DynamicVerse系统,能从普通单目视频中重建出完整的4D世界模型。该系统不仅能恢复真实物理尺度的三维几何结构,还能跟踪动态物体运动并生成详细的多层次文字描述。通过集成多种AI模型…详细

香港中文大学研究团队开发的DraCo技术让AI绘画系统学会了"先打草稿再完善"的人类创作方式。通过三步流程:草图生成、错误验证、精准修正,DraCo在多项测试中取得显著提升,特别擅长生成罕见组合和处理复杂要求,为AI…详细

腾讯AI实验室推出的SeeNav-Agent系统通过双视角视觉提示和步骤奖励组策略优化技术,显著提升了智能机器人的室内导航能力。该系统让机器人同时使用第一人称和鸟瞰视角观察环境,并为每个导航步骤提供即时反馈训练。实…详细

台湾阳明交大团队开发的Splannequin技术,通过双重检测系统识别曼尼金挑战视频中的"隐藏"和"缺陷"元素,运用时间锚定技术实现真正静止效果。该方法可将视频质量提升243.8%,推理速度达280FPS,支持用户自由选择冻结时…详细

Meta FAIR实验室开发的TV2TV模型首次实现了"边思考边生成"的视频创作模式。该模型通过文字思维和视觉创作的协同工作,能在生成视频过程中自动产生文字描述并据此调整画面内容。在游戏视频测试中获得91%好评率,具备强…详细

英属哥伦比亚大学研究团队发现AI搜索助手在学习过程中存在"懒惰似然位移死亡螺旋"问题,即模型会逐渐忘记正确答案最终导致训练崩溃。研究提出LLDS解决方案,通过轻量级正则化方法防止有害遗忘,在七个基准测试中实现…详细

丰田研究院联合多所大学开发的NeuralRemaster技术,通过"相位保持扩散"方法实现图像重渲染时的完美结构对齐。该技术保留图像相位信息控制空间布局,仅随机化幅度信息改变外观,无需修改现有模型架构。在自动驾驶应用…详细

英特尔研究团队提出SignRoundV2量化框架,通过创新的敏感性测量方法DeltaLoss和智能混合精度分配策略,实现了大型语言模型的极限压缩。该技术在2比特极端量化下仍能保持接近原模型性能,相比传统方法提升显著,且计算…详细

这项来自斯坦福大学等顶尖学府的研究发明了名为BulletTime的革命性视频生成技术,首次实现了对视频中时间流逝和摄像机视角的完全独立控制。该技术通过创新的Time-RoPE时间编码机制和4D控制架构,让用户能够在场景时间…详细

台湾大学团队开发出QKAN-LSTM技术,这是一种融合量子计算理念与传统神经网络的创新AI技术。该技术在时间序列预测任务中表现卓越,仅用传统方法21%的参数就达到更高预测精度。在城市通信、信号处理等测试中均显示出显…详细

北京大学等高校联合研究团队开发了EgoLCD框架,专门解决AI生成第一人称长视频时的"失忆"问题。该技术采用双重记忆系统设计,长期记忆保存重要场景信息,短期记忆快速适应新情况,配合记忆调节损失和结构化叙述提示技…详细

香港浸会大学研究团队提出REFLEX方法,通过将"真相"分解为实质内容和表达风格,实现准确的假新闻检测和可解释的推理。该方法仅用465个样本就达到最优性能,显著超越传统方法,在判断准确性和解释质量上都有明显提升,…详细

Qumulo将其横向扩展文件系统移植到Google Cloud平台,在Google Cloud市场推出Cloud Native Qumulo服务。该方案支持EB级扩展和全面的文件及对象应用,可实现1.6TBps吞吐量和2000万IOPS性能。用户只需为实际使用的容量…详细
如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。



