近日,由南方财经全媒体集团主办、21世纪经济报道承办的南方财经论坛2025年会在广州成功举行。论坛期间,神州数码凭借在科技创新、可持续发展等领域的卓越表现,成功斩获“2025年度科技价值上市公司”奖项。…详细

AI颠覆预计将在2026年持续,推动企业适应不断演进的技术并扩大规模。国际奥委会、Moderna和Sportradar的领导者在纽约路透社峰会上分享了他们的AI策略。讨论焦点包括自建AI与购买第三方资源的选择,AI在内部流程优化和…详细
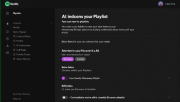
Spotify在新西兰测试推出AI提示播放列表功能,用户可通过文字描述需求让AI根据指令和听歌历史生成个性化播放列表。该功能允许用户设置定期刷新,相当于创建可控制算法的每周发现播放列表。这是Spotify赋予用户更多控…详细

Adobe报告2025年创纪录营收237.7亿美元,同比增长11%,主要归功于AI技术。尽管股价今年下跌超37%,但公司年利润实现增长。CEO表示Adobe在全球AI生态系统中重要性日益凸显,AI相关年度经常性收入已占总业务三分之一以…详细

迪士尼与OpenAI达成三年授权协议,允许Sora视频生成器创建包含超过200个迪士尼、漫威、皮克斯和星战角色的用户定制社交视频。该协议包括迪士尼对OpenAI的10亿美元投资,以及在Disney Plus平台展示Sora生成内容的计划…详细

甲骨文发布财报显示收入161亿美元同比增长14%但低于预期,股价盘前跌11%。公司将本财年资本支出预测上调40%至500亿美元,主要用于建设数据中心服务AI客户。长期债务增至999亿美元,同比增25%。尽管与Meta和英伟达签署…详细

挪威初创公司Spoor开发了基于计算机视觉的鸟类监测软件,可在2.5公里范围内追踪识别鸟类。该技术帮助风电场运营商更好规划选址并应对鸟类迁徙模式,在迁徙高峰期可减速或停止风机运转。公司鸟类识别准确率达96%,已与…详细

人工智能正在重塑各行各业,在生命科学领域尤其重要。制药公司希望通过AI加速药物发现、简化临床试验并降低开发成本。然而,95%的企业AI项目都以失败告终,主要原因是模型接收了低质量或不相关的数据。在制药行业,"…详细

AI开发运维工具Harness完成2.4亿美元E轮融资,估值达55亿美元,较2022年估值增长49%。该公司由AppDynamics创始人Jyoti Bansal于2017年创立,专注于自动化软件开发"代码后"阶段的测试、安全检查和部署工作。Harness利…详细

英伟达将自己定位为新计算时代的架构师。CEO黄仁勋表示,公司正在重新发明计算,从通用计算转向AI数据中心,即实时生成智能的"智能工厂"。AI将在大型云设施、智能设备和自主机器中实时运行,形成全球分布式AI工厂网络…详细

Port IO公司宣布完成1亿美元C轮融资,由General Atlantic领投,计划将其开发者门户转型为智能AI代理平台。该平台旨在通过AI代理自动化软件开发生命周期的大部分工作,包括票据解决、事故自愈、漏洞修复等功能。开发者…详细
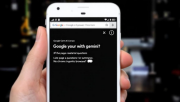
谷歌正式将Chrome浏览器的Gemini AI集成功能推广到iOS和iPadOS平台。用户可在地址栏左侧看到全新的Gemini图标,点击后可询问页面相关问题或要求AI总结网页内容。该功能需要用户登录Chrome账户,暂不支持无痕浏览模式…详细

随着智能手机市场成熟,高通急需多元化收入来源。公司在汽车领域深耕20年,从早期GM OnStar系统到如今的奔驰MBUX信息娱乐系统,已建立450亿美元未来五至七年订单储备。通过Vision Language Action模型,高通实现车辆…详细
谷歌Chrome团队推出名为Disco的实验性浏览器和GenTabs功能。该浏览器能根据用户查询自动打开相关标签页,并利用Gemini AI生成个性化应用。比如询问旅行建议时会创建规划应用,学习帮助时会生成闪卡系统。GenTabs是信…详细

联想全球CIO胡艾德分享了公司从全球化、多元化到服务化的三大转型历程。他强调技术是业务策略的体现,目前正推动AI在全企业的渗透应用,已有超过1000个AI项目在运行。胡艾德同时担任服务解决方案集团首席交付技术官,…详细

数据中心运营商面临AI驱动威胁和预算紧张的双重挑战,需采用"假定入侵"原则,最小化影响范围。最有效防护策略是扎实执行基础安全措施――强身份访问管理、及时补丁更新、清洁配置和全面日志记录,同时将网络和物理安…详细
如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。




