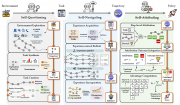
阿里团队可能揭露了下一代AI路线:AgentEvolver如何实现智能体的自我进化…详细
11月16日,第十四届中国创新创业大赛纳米产业技术创新专业赛(下称“纳米专业赛”)初赛,在广东粤港澳大湾区国家纳米科技创新研究院(下称“广纳院”)成功举办。…详细
SuperX AI Technology Limited任命企业科技资深领军人物黄陈宏博士为董事局主席兼CEO,加速全球AI基础设施布局黄博士在 SAP、戴尔和施耐德电气三十年的跨国科技企业高管经验将加速SuperX 的模块化AI 工厂与全栈基础设…详细

随着AI技术不断发展,交通运输行业正迎来重大变革。MIT研究显示,AI将很快自动化价值650亿美元的交通工作,大幅提升运输效率。从陆地到海空,AI正在推动全方位的交通创新。斯坦福专家强调,AI将通过基础模型、合成数…详细

波兰研究团队开发ORCA数学基准测试,对五个主流大语言模型进行评估。结果显示ChatGPT-5、Gemini 2.5 Flash、Claude Sonnet 4.5、Grok 4和DeepSeek V3.2的准确率均低于63%。测试涵盖生物化学、工程建筑、金融经济等七…详细

美国能源信息署预测,2026年批发电力价格将上涨8.5%至每兆瓦时51美元,主要由数据中心和加密货币挖矿需求驱动。尽管可再生能源发电比例将达到创纪录的26%,加上核电18%的贡献,无碳发电将占总量44%,但整体碳排放变化…详细

GMI Cloud在台湾投资5亿美元建设AI工厂数据中心,将使用VAST Data存储系统为7000个Blackwell GPU提供数据支持。该项目与英伟达合作,GPU将配备NVLink、InfiniBand和Spectrum-X以太网网络,部署在96个机架中,每秒可处…详细
亚马逊云科技发布一套人工智能代理工具,旨在简化其专业服务团队的工作流程。该工具集以AWS Professional Services Delivery Agent为核心,能够将通常需要数月完成的任务压缩至几天内完成,同时降低项目成本。该代理…详细

香港科技大学团队发表重要研究,开发GIR-Bench测试基准评估统一多模态AI模型的推理与生成能力。研究发现即使最先进的AI模型在理解与生成之间也存在显著差距,无法有效将推理过程转化为准确的视觉生成,为AI行业发展提…详细

Meta超级智能实验室联合麻省理工学院开发了SPG三明治策略梯度方法,专门解决扩散语言模型强化学习训练中的技术难题。该方法通过上下界策略为AI模型提供精确的奖惩反馈机制,在数学和逻辑推理任务上实现了显著性能提升…详细

上海AI实验室联合多所知名高校推出的Vlaser模型,成功将机器人的视觉理解、语言处理和精确行动能力统一在单一架构中。该模型基于600万个高质量训练样本构建,在12项综合测试中全面领先同类产品,实际机器人操作成功率…详细

首尔国立大学研究团队通过深入分析大型视觉语言模型发现,AI产生视觉幻觉的根本原因在于视觉编码器中存在"不确定性"标记。他们创新性地使用对抗性攻击识别这些不确定标记,并通过智能屏蔽策略显著降低了物体幻觉率。…详细

这项由港大、美团、港中大联合开展的研究提出了CodePlot-CoT系统,让AI通过生成绘图代码来进行数学视觉推理。该系统解决了现有AI无法有效处理需要画图辅助的数学题难题,在专门构建的Math-VR数据集上取得21%的性能提…详细

这项研究提出了革命性的"环境调教"AI训练方法,通过让AI的练习环境变得更智能来提升学习效果。仅用400个样本就让基础模型成功率从7%提升至37%,超越多个商业模型。该方法包含四阶段渐进训练、智能环境反馈、细粒度奖…详细

腾讯团队开发的ReLook框架首次让AI具备"看见"自己编写网页效果的能力。该系统通过建立生成-诊断-改进循环,让AI能够实时预览代码的视觉呈现,并基于多模态大模型的视觉反馈不断优化。ReLook在多个基准测试中显著超越…详细

普林斯顿大学研究团队开发了STAT方法,通过让AI"老师"分析"学生"模型的技能缺陷,针对性制定训练方案。该方法在数学能力测试中实现了7.5%的显著提升,并在未见过的竞赛中平均提升4.6%。这种个性化AI训练方法突破了传…详细
如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。





