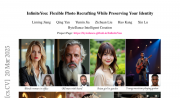
字节跳动团队突破了AI图像生成领域的三大难题:身份识别不准确、文字理解偏差和图片质量不佳。他们开发的InfiniteYou技术采用创新的InfuseNet架构和多阶段训练策略,能够根据用户照片和文字描述生成高质量个性化图像…详细

这份由新加坡国立大学等顶尖学府研究团队发布的调研报告,系统梳理了多模态思维链推理这一前沿AI技术的发展现状。该技术让AI具备了同时处理文字、图像、音频等多种信息并进行逐步推理的能力,在医疗诊断、自动驾驶、…详细

上海交大等机构联合提出ADC方法,通过双人协作的对抗性数据收集策略,让机器人仅用20%的训练数据就能获得更强的环境适应能力和指令理解能力。该方法引入"对抗操作员"在训练过程中制造视觉和语言扰动,迫使主操作员实…详细

Hedra公司推出的MagicInfinite技术能够让静态人像照片"开口说话",支持通过声音和文字双重控制生成高质量动态视频。该系统采用3D全注意力机制和两阶段训练方案,可处理各种风格人像(真实照片、动漫、艺术作品),实…详细

这项由上海人工智能实验室等多家机构联合开展的研究,开发了VBench-2.0评估系统,专门测试视频生成AI对真实世界的理解能力。与关注视觉效果的传统评估不同,VBench-2.0从人体逼真度、可控性、创造力、物理学和常识推…详细

伊利诺伊大学研究团队开发的Search-R1系统让AI学会了像人类一样边思考边搜索的能力。通过强化学习,AI能够主动决定何时搜索外部信息、如何整合搜索结果进行推理。该系统在七个问答数据集上平均提升20-24%的准确率,代…详细

斯坦福和伯克利研究团队推出VidDiff技术,让AI学会像专业教练一样精准识别动作差异。该技术通过三步走方法解决视频动作比较难题,构建了包含549对视频的大型数据集VidDiffBench。虽然当前AI模型准确率有限,但已展现…详细

澳洲国立大学团队开发的Motion Anything系统实现了AI动作生成的重大突破,能够根据文字、音乐或两者组合自动生成逼真的人体动作。该系统采用创新的注意力引导遮罩策略和双重变换器架构,在多个基准测试中显著超越现有…详细

香港科技大学团队发现AI可通过"零RL训练"直接学会深度思考,无需预先教授基础知识。研究测试了10个不同规模AI模型,发现它们能在数学推理训练中自发展现验证、反思等高级认知行为,部分模型出现"顿悟时刻"。研究还发…详细

阿里巴巴通义实验室开发的LHM系统能够在几秒钟内将单张人物照片转换成可自由运动的3D虚拟人物。该技术采用多模态变换器架构,结合3D高斯分布表示和自监督学习策略,在重建质量和生成速度上都显著优于现有方法,为虚拟…详细

中科院团队首次系统研究了大型多模态AI模型在视频理解中的"幻觉"问题,构建了包含6497个问题的HAVEN评估体系,发现AI看视频时会出现物体、场景、事件三类错误。研究还提出了创新的"视频思维模型"解决方案,通过让AI进…详细

微软研究院最新推出的AI视频生成模型Sora引发科技界轰动。这款"世界模拟器"能根据文本描述生成长达一分钟的高质量视频,远超以往AI视频技术的几秒钟限制。Sora采用扩散模型和"时空补丁"方法,能创建角色一致、动作流…详细

瑞典皇家理工学院与斯堪尼亚公司合作开发的PRIX自动驾驶系统,仅使用普通摄像头就达到了业界顶尖性能,处理速度比竞争对手快25%以上。该系统通过创新的视觉特征提取技术和扩散模型规划器,在多项标准测试中表现优异,…详细

智能体AI有望通过大幅改善工作流自动化来推动企业转型。Agntcy是2025年3月成立的开源组织,致力于构建"智能体互联网"框架。该框架由思科Outshift孵化部门创立,专注于智能体协调编排和身份访问管理。7月29日Linux基金…详细
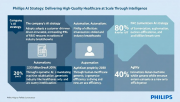
飞利浦首席创新战略官谢兹・帕托维分享了公司的AI战略。飞利浦采用客户驱动的创新模式,将80%研发资源嵌入业务单元,20%专注行业突破。公司AI战略围绕自动化、增强和敏捷三个维度展开,旨在2030年惠及25亿人。通过Sm…详细
Linux内核6.16在周末发布,虽然没有重大新功能,但包含大量错误修复和代码优化。该版本拥有3840万行代码,分布在超过78000个文件中。主要改进包括:支持英特尔2023年高级性能扩展,XFS和ext4文件系统性能优化,NUMA系…详细

Gartner预测,受高调网络攻击事件不断增加和新兴风险驱动,全球终端用户组织的网络安全产品和服务支出持续上升,2025年将超过2000亿美元。人工智能和生成式AI的广泛应用成为关键增长驱动因素,信息安全总支出将从202…详细

生成式AI初创公司Writer发布Action Agent,这是一款集成工具使用、知识工作和深度研究能力的强大AI智能体,具备企业级控制和透明度。该智能体由Palmyra X5大语言模型驱动,能够执行需要问题解决、复杂推理和多工具使…详细

计算机视觉初创公司Matrice.ai宣布完成种子轮战略扩展融资,云基础设施提供商Voltage Park领投。该公司开发的无代码平台可创建人工智能视觉模型,开发速度比传统方法快40%,成本降低80%。该平台采用数据驱动方法,提…详细

Adobe发布Photoshop全新AI工具套件,包括Harmonize智能融合功能、生成式放大工具和改进的移除工具。Harmonize可自动调整色彩、光线和阴影,实现无缝合成;生成式放大可将图像提升至800万像素而不损失清晰度;改进的移…详细
如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。



