在美国旧金山刚刚结束的微软Ignite大会上,长虹佳华凭借其在服务出海企业及创新解决方案上的卓越表现,获得微软中国年度最佳合作伙伴大奖。…详细
日立集团 (TSE: 6501) 旗下专注数据存储、基础架构与混合云管理的子公司 Hitachi Vantara 今日宣布推出 Virtual Storage Platform One 高端块存储 (Virtual Storage Platform One Block High End, VSP One Block Hig…详细
未来组织将通过AI释放创造力、激发创新动能,成为前沿公司,让下一个伟大创新灵感得以涌现。今年微软Ignite盛会正全力赋能AI的全周期,通过打造创新工具和解决方案,助力每个组织在工作各层面迈向下一代数字化转型。…详细

新加坡南洋理工大学团队开发的NEO模型颠覆了传统视觉语言AI的设计思路,从模块化拼接转向原生统一架构。仅用3.9亿图文配对数据就实现了与大型模块化系统相媲美的性能,证明了端到端训练的有效性,为AI系统设计开辟了…详细

谷歌联合德克萨斯大学等机构开发出LATTICE框架,这是一种革命性的信息检索系统,能像智能图书管理员一样工作。它将文档组织成语义树结构,用AI推理能力进行智能导航搜索,在复杂查询任务上比传统方法准确率提高9%以上…详细

蚂蚁集团等机构联合提出IGPO方法,解决多轮AI智能体训练中的奖励稀疏问题。该方法通过信息增益为每个交互轮次提供密集反馈,避免传统方法中的"优势坍塌"现象。在七个数据集上的实验表明,IGPO显著超越现有方法,平均…详细

ETH苏黎世大学和Google联合开发的VIST3A技术,通过巧妙拼接视频生成模型和3D重建模型,实现了仅用文字描述就能生成高质量3D场景的突破。该技术采用模型拼接和直接奖励微调两大核心创新,在多个基准测试中显著超越现有…详细

泰国研究团队开发了首个多元宇宙超级英雄AI角色扮演基准测试"Beyond One World",涵盖30个英雄的90个版本,通过经典事件记忆和道德两难选择双重测试,发现AI模型普遍存在跨版本角色区分困难、思考与行动不一致等问题…详细

华盛顿大学研究团队发现,AI模型训练过程中产生的"中间产品"不应被丢弃,而应通过协作发挥价值。他们开发的"切换生成"技术让预训练、微调和对齐模型像接力赛一样协作回答问题,在18个任务中的16个表现超越单一模型,…详细

香港中文大学团队开发了MathCanvas框架,首次让AI具备了"边画边想"的数学推理能力。该系统通过两阶段训练让AI学会生成和编辑数学图形,并在解题中战略性运用视觉工具。在包含3000道题目的测试中,性能相比基础模型提…详细

2025 年 11 月 25 日戴尔科技集团 公布了 2026 财年第三财季业绩报告,以及2026 财年第四财季及全年的业绩指引。公司同时正式任命David Kennedy为首席财务官。…详细
11月25日,华为Mate80系列|Mate X7及全场景新品发布会如期而至,备受期待的Mate 80系列、Mate X7系列及首款鸿蒙二合一平板电脑MatePad Edge等新品集体亮相。…详细

SCU35 评估套件起售价为 229 美元,现已通过 AMD 及其全球分销合作伙伴发售。…详细

英国宠物慈善机构PDSA数据显示,超过半数宠物主担心无法承担兽医费用。科技公司正通过AI和物联网技术解决这一市场需求。在伦敦兽医展上,多家初创公司展示了创新技术:AI for Pet利用视觉AI分析宠物眼部、皮肤等图像…详细

北欧国家启动统一人工智能产业计划,旨在通过合作在全球舞台上竞争,获得微软和谷歌支持。10月成立的新北欧AI中心获得350万英镑初始预算,但谷歌和微软是唯一提供资金支持的科技公司,具体金额保密。该中心将开发生成…详细
加州大学河滨分校研究显示,2019至2023年间,加州数据中心污染对健康的潜在影响增长了两倍。报告警告,若缺乏新的缓解政策,到2028年这一影响可能再增长72%。研究将健康影响激增与数据中心用电量近乎翻倍联系起来,预…详细
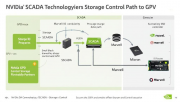
英伟达SCADA技术是一种新型存储数据IO方案,GPU可直接启动和控制存储IO操作。与现有GPUDirect协议不同,SCADA不仅接管数据路径,还控制IO控制路径。该技术特别适用于AI推理工作负载中小于4KB的小块数据传输,能显著提…详细

Hammerspace在IO500基准测试中取得突破,其标准Linux加NFS系统软件实现了HPC级性能,无需专有并行文件系统的复杂性。在SC25的10节点生产环境测试中排名第18位,这是NFS系统有史以来最快的结果。该公司使用标准Linux、…详细

甲骨文在阿布扎比云区域部署了中东地区首个由英伟达Blackwell GPU驱动的OCI超级集群,旨在加速阿联酋主权AI发展,支持阿布扎比到2027年成为全球首个完全AI原生政府的目标。这项部署是该地区最重要的高性能AI计算投资…详细

英国领先电信运营商EE在推出5G独立组网(现称为5G+)一年多后,宣布在全国5G+项目中迈出重要一步,为超过50万拥有兼容智能手机的客户提供5G+服务。EE已将5G+覆盖扩展至66%的英国人口,提前五个月超越原定目标。新增2…详细
如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。



